Copyright (c) 2000 First Things 102 (April 2000): 30-38.
For two millennia, the design argument provided an intellectual foundation for much of Western thought. From classical antiquity through the rise of modern science, leading philosophers, theologians, and scientists—from Plato to Aquinas to Newton—maintained that nature manifests the design of a preexistent mind or intelligence. Moreover, for many Western thinkers, the idea that the physical universe reflected the purpose or design of a preexistent mind—a Creator—served to guarantee humanity’s own sense of purpose and meaning. Yet today in nearly every academic discipline from law to literary theory, from behavioral science to biology, a thoroughly materialistic understanding of humanity and its place in the universe has come to dominate. Free will, meaning, purpose, and God have become pejorative terms in the academy. Matter has subsumed mind; cosmos replaced Creator.
The reasons for this intellectual shift are no doubt complex. Yet clearly the demise of the design argument itself has played an important role in the loss of this traditional Western belief. Beginning in the Enlightenment, philosophers such as David Hume raised seemingly powerful objections against the design argument. Hume claimed that classical design arguments depended on a weak and flawed analogy between biological organisms and human artifacts. Yet for most, it was not the arguments of the philosophers that disposed of design, but the theories of scientists, particularly that of Charles Darwin. If the origin of biological organisms could be explained naturalistically, as Darwin claimed, then explanations invoking an intelligent designer were unnecessary and even vacuous. Indeed, as Richard Dawkins has put it, it was "Darwin [who] made it possible to be an intellectually fulfilled atheist."
Thus, since the late nineteenth century most biologists have rejected the idea that living organisms display evidence of intelligent design. While many acknowledge the appearance of design in biological systems, they insist that Darwinism, or neo–Darwinism, explains how this appearance arose naturalistically—that is, without invoking a directing intelligence or agency. Following Darwin, modern neo–Darwinists generally accept that natural selection acting on random variation can explain the appearance of design in living organisms.
Yet however one assesses the explanatory power of Darwinism (or modern neo–Darwinism), the appearance of design in at least one important domain of biology cannot be so easily dismissed. During the last half of the twentieth century, advances in molecular biology and biochemistry have revolutionized our understanding of the miniature world within the cell. Research has revealed that cells—the fundamental units of life—store, transmit, and edit information and use that information to regulate their most fundamental metabolic processes. Far from characterizing cells as simple "homogeneous globules of plasm" as did Ernst Haeckel and other nineteenth–century biologists, biologists now describe cells as, among other things, "distributive real time computers" or complex information processing systems.
Darwin, of course, neither knew about these intricacies nor sought to explain their origin. Instead, his theory of biological evolution sought to explain how life could have grown gradually more complex starting from "one or a few simple forms." Strictly speaking, therefore, those who insist that the purely naturalistic Darwinian mechanism can explain the appearance of design in biology overstate their case. The complexities within the microcosm of the cell beg for some kind of explanation. Yet they lie beyond the purview of strictly biological evolutionary theory, which assumes, rather than explains, the existence of the first life and the information it required.
Darwin’s theory sought to explain the origin of new forms of life from simpler forms. It did not explain how the first life—presumably a simple cell—might have arisen in the first place. Nevertheless, in the 1870s and 1880s scientists assumed that devising an explanation for the origin of life would be fairly easy. For one thing, they assumed that life was essentially a rather simple substance called protoplasm that could be easily constructed by combining and recombining simple chemicals such as carbon dioxide, oxygen, and nitrogen. Early theories of life’s origin reflected this view. Haeckel likened cell "autogeny," as he called it, to the process of inorganic crystallization. Haeckel’s English counterpart, T. H. Huxley, proposed a simple two–step method of chemical recombination to explain the origin of the first cell. Just as salt could be produced spontaneously by adding sodium to chloride, so, thought Haeckel and Huxley, could a living cell be produced by adding together several chemical constituents and then allowing spontaneous chemical reactions to produce the simple protoplasmic substance that they assumed to be the essence of life.
During the 1920s and 1930s a more sophisticated version of this so–called "chemical evolutionary theory" was proposed by a Russian biochemist named Alexander I. Oparin. Oparin had a much more accurate understanding than his predecessors of the complexity of cellular metabolism, but neither he nor any one else at the time fully appreciated the complexity of the molecules such as protein and DNA that make life possible. Oparin, like his nineteenth–century predecessors, suggested that life could have first evolved as the result of a series of chemical reactions. Unlike his predecessors, however, he envisioned that this process of chemical evolution would involve many more chemical transformations and reactions and many hundreds of millions (or even billions) of years.
The first experimental support for Oparin’s hypothesis came in December 1952. While doing graduate work under Harold Urey at the University of Chicago, Stanley Miller circulated a gaseous mixture of methane, ammonia, water vapor, and hydrogen through a glass vessel containing an electrical discharge chamber. Miller sent a high voltage charge of electricity into the chamber via tungsten filaments in an attempt to simulate the effects of ultraviolet light on prebiotic atmospheric gases. After two days, Miller found a small (2 percent) yield of amino acids in the U–shaped water trap he used to collect reaction products at the bottom of the vessel.
Miller’s success in producing biologically relevant "building blocks" under ostensibly prebiotic conditions was heralded as a great breakthrough. His experiment seemed to provide experimental support for Oparin’s chemical evolutionary theory by showing that an important step in Oparin’s scenario—the production of biological building blocks from simpler atmospheric gases—was possible on the early earth. Miller’s experimental results gave Oparin’s model the status of textbook orthodoxy almost overnight. Thanks largely to Miller, chemical evolution is now routinely presented in both high school and college biology textbooks as the accepted scientific explanation for the origin of life.
Yet as we shall see, chemical evolutionary theory is now known to be riddled with difficulties; and Miller’s work is understood by the origin–of–life research community itself to have little if any relevance to explaining how amino acids—let alone proteins or living cells—actually could have arisen on the early earth.
When Miller conducted his experiment, he presupposed that the earth’s atmosphere was composed of a mixture of what chemists call "reducing gases" such as methane, ammonia, and hydrogen. He also assumed that the earth’s atmosphere contained virtually no free oxygen. In the years following Miller’s experiment, however, new geochemical evidence made it clear that the assumptions that Oparin and Miller had made about the early atmosphere could not be justified.
Instead, evidence strongly suggested that neutral gases—not methane, ammonia, and hydrogen—predominated in the early atmosphere. Moreover, a number of geochemical studies showed that significant amounts of free oxygen were also present even before the advent of plant life, probably as the result of volcanic outgassing and the photodissociation of water vapor. In a chemically neutral atmosphere, reactions among atmospheric gases will not readily take place. Moreover, even a small amount of atmospheric oxygen will quench the production of biological building blocks and cause any biomolecules otherwise present to degrade rapidly.
As had been well known even before Miller’s experiment, amino acids will form readily in an appropriate mixture of reducing gases. What made Miller’s experiment significant was not the production of amino acids per se, but their production from ostensibly plausible prebiotic conditions. As Miller himself stated, "In this apparatus an attempt was made to duplicate a primitive atmosphere of the earth, and not to obtain the optimum conditions for the formation of amino acids." Now, however, the only reason to continue assuming the existence of a chemically reducing, prebiotic atmosphere is that chemical evolutionary theory requires it.
Ironically, even if we assume for the moment that the reducing gases used by Stanley Miller do actually simulate conditions on the early earth, his experiments inadvertently demonstrated the necessity of intelligent agency. Even successful simulation experiments require the intervention of the experimenters to prevent what are known as "interfering cross reactions" and other chemically destructive processes. Without human intervention, experiments like that performed by Miller invariably produce nonbiological substances that degrade amino acids into nonbiologically relevant compounds.
Experimenters prevent this by removing chemical products that induce undesirable cross reactions. They employ other "unnatural" interventions as well. Simulation experimenters have typically used only short wavelength light, rather than both short and long wavelength ultraviolet light, which would be present in any realistic atmosphere. Why? The presence of the long wavelength UV light quickly degrades amino acids.
Such manipulations constitute what chemist Michael Polanyi called a "profoundly informative intervention." They seem to "simulate," if anything, the need for an intelligent agent to overcome the randomizing influences of natural chemical processes.
Yet a more fundamental problem remains for all chemical evolutionary scenarios. Even if it could be demonstrated that the building blocks of essential molecules could arise in realistic prebiotic conditions, the problem of assembling those building blocks into functioning proteins or DNA chains would remain.
To form a protein, amino acids must link together to form a chain. Yet amino acids form functioning proteins only when they adopt very specific sequential arrangements, rather like properly sequenced letters in an English sentence. Thus, amino acids alone do not make proteins, any more than letters alone make words, sentences, or poetry. In both cases, the sequencing of the constituent parts determines the function (or lack of function) of the whole. Explaining the origin of the specific sequencing of proteins (and DNA) lies at the heart of the current crisis in materialistic evolutionary thinking.
Biologists from Darwin’s time to the late 1930s assumed that the secret of protein function derived from some kind of simple, regular structure explicable by reference to mathematical laws. Beginning in the 1950s, however, biologists made a series of discoveries that caused this simplistic view of proteins to change. In the early 1950s, molecular biologist Fred Sanger determined the structure of the protein molecule insulin. Sanger’s work showed that proteins are made of long and irregularly arranged sequences of amino acids, rather like an irregularly arranged string of colored beads. Later in the 1950s, work by Andrew Kendrew on the structure of the protein myoglobin showed that proteins also exhibit a surprising three–dimensional complexity. Far from the simple structures that biologists had imagined, Kendrew’s work revealed an extraordinarily complex and irregular three–dimensional shape—a twisting, turning, tangled chain of amino acids.
During the 1950s scientists quickly realized that proteins possess another remarkable property. In addition to their complexity, they also exhibit specificity. Whereas proteins are built from rather simple chemical building blocks known as amino acids, their function (whether as enzymes, signal transducers, or structural components in the cell) depends crucially upon the complex but specific sequencing of these building blocks—and slight alterations in sequencing can quickly result in loss of function.
The specific sequencing of amino acids in proteins gives rise to specific three–dimensional structures. This structure or shape in turn determines what function, if any, the amino acid chain can perform within the cell. For a functioning protein, its three–dimensional shape gives it a "hand–in–glove" fit with other molecules in the cell, enabling it to catalyze specific chemical reactions or to build specific structures within the cell. Because of this specificity, one protein can usually no more substitute for another than one tool can substitute for another. A topoisomerase can no more perform the job of a polymerase than a hatchet can perform the function of a soldering iron. Proteins can perform functions only by virtue of their three–dimensional specificity of fit with other equally specified and complex molecules within the cell. This three–dimensional specificity derives in turn from a one–dimensional specificity of sequencing in the arrangement of the amino acids that form proteins.
How did such complex, but specific, structures arise in the cell? This question recurred with particular urgency after Sanger revealed his results in the early 1950s. Proteins seemed too complex and functionally specified to arise by chance. Moreover, given their irregularity, it seemed unlikely that a general chemical law or regularity governed their assembly. Instead, as Jacques Monod has recalled, molecular biologists began to look for some source of information within the cell that could direct the construction of these highly specific structures. To explain the presence of all that information in the protein, Monod would later explain, "You absolutely needed a code."
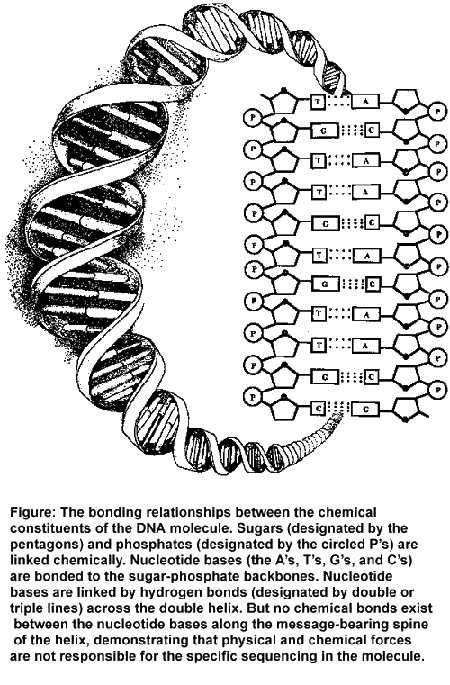
In 1953, James Watson and Francis Crick elucidated the structure of the DNA molecule. Soon thereafter, molecular biologists discovered how DNA stores the information necessary to direct protein synthesis. In 1955 Francis Crick first proposed the "sequence hypothesis" suggesting that the specificity of amino acids in proteins derives from the specific arrangement of chemical constituents in the DNA molecule. According to the sequence hypothesis, information on the DNA molecule is stored in the form of specifically arranged chemicals called nucleotide bases along the spine of DNA’s helical strands. Chemists represent these four nucleotides with the letters A, T, G, and C (for adenine, thymine, guanine, and cytosine). By 1961, the sequence hypothesis had become part of the so–called "central dogma" of molecular biology as a series of brilliant experiments confirmed DNA’s information–bearing properties.
As it turns out, specific regions of the DNA molecule called coding regions have the same property of "sequence specificity" or "specified complexity" that characterizes written codes, linguistic texts, and protein molecules. Just as the letters in the alphabet of a written language may convey a particular message depending on their arrangement, so too do the sequences of nucleotide bases (the A’s, T’s, G’s, and C’s) inscribed along the spine of a DNA molecule convey a precise set of instructions for building proteins within the cell. The nucleotide bases in DNA function in precisely the same way as symbols in a machine code. In each case, the arrangement of the characters determines the function of the sequence as a whole. As Richard Dawkins has noted, "The machine code of the genes is uncannily computer–like." In the case of a computer code, the specific arrangement of just two symbols (0 and 1) suffices to carry information. In the case of DNA, the complex but precise sequencing of the four nucleotide bases (A, T, G, and C) stores and transmits the information necessary to build proteins. Thus, the sequence specificity of proteins derives from a prior sequence specificity—from the information—encoded in DNA.
The elucidation of DNA’s information–bearing properties raised the question of the ultimate origin of the information in both DNA and proteins. Indeed, many scientists now refer to the information problem as the "Holy Grail" of origin–of–life biology. As Bernd–Olaf Kuppers recently stated, "The problem of the origin of life is clearly basically equivalent to the problem of the origin of biological information." Since the 1950s, three broad types of naturalistic explanation have been proposed by scientists to explain the origin of information: chance, prebiotic natural selection, and chemical necessity.
While many outside origin–of–life biology may still invoke "chance" as a causal explanation for the origin of biological information, few serious researchers still do. Since molecular biologists began to appreciate the sequence specificity of proteins and nucleic acids in the 1950s and 1960s, many calculations have been made to determine the probability of formulating functional proteins and nucleic acids at random. Even assuming extremely favorable prebiotic conditions and theoretically maximal reaction rates, such calculations have invariably shown that the probability of obtaining functionally sequenced biomacromolecules at random is, in Ilya Prigogine’s words, "vanishingly small . . . even on the scale of . . . billions of years."
Consider the hurdles that must be overcome to construct even one short protein molecule of about one hundred amino acids in length. First, all amino acids must form a chemical bond known as a peptide bond so as to join with other amino acids in the protein chain. Yet in nature many types of chemical bonds are possible between amino acids, only about half of which are peptide bonds. The probability of building a chain of one hundred amino acids in which all linkages involve peptide bonds is roughly (1/2)99 or 1 chance in 1030.
Second, in nature every amino acid has a distinct mirror image of itself, one left–handed version or L–form and one right–handed version or D–form. These mirror–image forms are called optical isomers. Functioning proteins tolerate only left–handed amino acids, yet the right–handed and left–handed isomers occur in nature with roughly equal frequency. Taking this into consideration compounds the improbability of attaining a biologically functioning protein. The probability of attaining at random only L–amino acids in a hypothetical peptide chain one hundred amino acids long is (1/2)100 or again roughly 1 chance in 1030.
Third and most important of all: functioning proteins must have amino acids that link up in a specific sequential arrangement, just as the letters in a meaningful sentence do. Because there are twenty biologically occurring amino acids, the probability of getting a specific amino acid at a given site is 1/20. Even if we assume that some sites along the chain will tolerate several amino acids, we find that the probability of achieving a functional sequence of amino acids in several functioning proteins at random is still "vanishingly small," roughly 1 chance in 1065—an astronomically large number—for a protein one hundred amino acids in length. (Actually the probability is even lower because there are many non–proteinous amino acids in nature that we have not accounted for in this calculation.)
If one also factors in the probability of attaining proper bonding and optical isomers, the probability of constructing a rather short, functional protein at random becomes so small (1 chance in 10125) as to approach the point at which appeals to chance become absurd even given the "probabilistic resources" of our multi–billion–year–old universe. Consider further that equally severe probabilistic difficulties attend the random assembly of functional DNA. Moreover, a minimally complex cell requires not one, but roughly one hundred complex proteins (and many other biomolecular components such as DNA and RNA) all functioning in close coordination. For this reason, quantitative assessments of cellular complexity have simply reinforced an opinion that has prevailed since the mid–1960s within origin–of–life biology: chance is not an adequate explanation for the origin of biological complexity and specificity.
At nearly the same time that many researchers became disenchanted with "chance" explanations, theories of prebiotic natural selection also fell out of favor. Such theories allegedly overcome the difficulties of pure chance by providing a mechanism by which complexity–increasing events in the cell might be preserved and selected. Yet these theories share many of the difficulties that afflict purely chance–based theories.
Natural selection presupposes a preexisting mechanism of self–replication. Yet self–replication in all extant cells depends upon functional (and, therefore, to a high degree sequence–specific) proteins and nucleic acids. But the origin of these molecules is precisely what Oparin needed to explain. Thus, many rejected his postulation of prebiotic natural selection as question begging. As the evolutionary biologist Theodosius Dobzhansky would insist, "Prebiological natural selection is a contradiction in terms."
Further, natural selection can select only what chance has first produced, and chance, at least in a prebiotic setting, seems an implausible agent for producing the information present in even a single functioning protein or DNA molecule. As Christian de Duve has explained, theories of prebiotic natural selection "need information which implies they have to presuppose what is to be explained in the first place." For this reason, most scientists now dismiss appeals to prebiotic natural selection as essentially indistinguishable from appeals to chance.
Because of these difficulties, many origin–of–life theorists after the mid–1960s attempted to address the problem of the origin of biological information in a completely new way. Rather than invoking prebiotic natural selection or "frozen accidents," many theorists suggested that the laws of nature and chemical attraction may themselves be responsible for the information in DNA and proteins. Some have suggested that simple chemicals might possess "self–ordering properties" capable of organizing the constituent parts of proteins, DNA, and RNA into the specific arrangements they now possess. Just as electrostatic forces draw sodium (Na+) and chloride ions (Cl–) together into highly ordered patterns within a crystal of salt (NaCl), so too might amino acids with special affinities for each other arrange themselves to form proteins.
In 1977, Prigogine and Gregorie Nicolis proposed another theory of self–organization based on their observation that open systems driven far from equilibrium often display self–ordering tendencies. For example, gravitational energy will produce highly ordered vortices in a draining bathtub, and thermal energy flowing through a heat sink will generate distinctive convection currents or "spiral wave activity."
For many current origin–of–life scientists, self–organizational models now seem to offer the most promising approach to explaining the origin of biological information. Nevertheless, critics have called into question both the plausibility and the relevance of self–organizational models. Ironically, perhaps the most prominent early advocate of self–organization, Dean Kenyon, has now explicitly repudiated such theories as both incompatible with empirical findings and theoretically incoherent.
The empirical difficulties that attend self–organizational scenarios can be illustrated by examining a DNA molecule. The diagram opposite shows that the structure of DNA depends upon several chemical bonds. There are bonds, for example, between the sugar and the phosphate molecules that form the two twisting backbones of the DNA molecule. There are bonds fixing individual (nucleotide) bases to the sugar–phosphate backbones on each side of the molecule. Notice that there are no chemical bonds between the bases that run along the spine of the helix. Yet it is precisely along this axis of the molecule that the genetic instructions in DNA are encoded.
Further, just as magnetic letters can be combined and recombined in any way to form various sequences on a metal surface, so too can each of the four bases A, T, G, and C attach to any site on the DNA backbone with equal facility, making all sequences equally probable (or improbable). The same type of chemical bond occurs between the bases and the backbone regardless of which base attaches. All four bases are acceptable; none is preferred. In other words, differential bonding affinities do not account for the sequencing of the bases. Because these same facts hold for RNA molecules, researchers who speculate that life began in an "RNA world" have also failed to solve the sequencing problem—i.e., the problem of explaining how information present in all functioning RNA molecules could have arisen in the first place.
For those who want to explain the origin of life as the result of self–organizing properties intrinsic to the material constituents of living systems, these rather elementary facts of molecular biology have devastating implications. The most logical place to look for self–organizing properties to explain the origin of genetic information is in the constituent parts of the molecules carrying that information. But biochemistry and molecular biology make clear that the forces of attraction between the constituents in DNA, RNA, and protein do not explain the sequence specificity of these large information–bearing biomolecules.
Significantly, information theorists insist that there is a good reason for this. If chemical affinities between the constituents in the DNA message text determined the arrangement of the text, such affinities would dramatically diminish the capacity of DNA to carry information. Consider what would happen if the individual nucleotide "letters" in a DNA molecule did interact by chemical necessity with each other. Every time adenine (A) occurred in a growing genetic sequence, it would likely drag thymine (T) along with it. Every time cytosine (C) appeared, guanine (G) would follow. As a result, the DNA message text would be peppered with repeating sequences of A’s followed by T’s and C’s followed by G’s.
Rather than having a genetic molecule capable of unlimited novelty, with all the unpredictable and aperiodic sequences that characterize informative texts, we would have a highly repetitive text awash in redundant sequences—much as happens in crystals. Indeed, in a crystal the forces of mutual chemical attraction do completely explain the sequential ordering of the constituent parts, and consequently crystals cannot convey novel information. Sequencing in crystals is repetitive and highly ordered, but not informative. Once one has seen "Na" followed by "Cl" in a crystal of salt, for example, one has seen the extent of the sequencing possible. Bonding affinities, to the extent they exist, mitigate against the maximization of information. They cannot, therefore, be used to explain the origin of information. Affinities create mantras, not messages.
The tendency to confuse the qualitative distinction between "order" and "information" has characterized self–organizational research efforts and calls into question the relevance of such work to the origin of life. Self–organizational theorists explain well what doesn’t need explaining. What needs explaining is not the origin of order (whether in the form of crystals, swirling tornadoes, or the "eyes" of hurricanes), but the origin of information—the highly improbable, aperiodic, and yet specified sequences that make biological function possible.
To see the distinction between order and information, compare the sequence "ABABABABAB ABAB" to the sequence "Time and tide wait for no man." The first sequence is repetitive and ordered, but not complex or informative. Systems that are characterized by both specificity and complexity (what information theorists call "specified complexity") have "information content." Since such systems have the qualitative feature of aperiodicity or complexity, they are qualitatively distinguishable from systems characterized by simple periodic order. Thus, attempts to explain the origin of order have no relevance to discussions of the origin of information content. Significantly, the nucleotide sequences in the coding regions of DNA have, by all accounts, a high information content—that is, they are both highly specified and complex, just like meaningful English sentences or functional lines of code in computer software.
Yet the information contained in an English sentence or computer software does not derive from the chemistry of the ink or the physics of magnetism, but from a source extrinsic to physics and chemistry altogether. Indeed, in both cases, the message transcends the properties of the medium. The information in DNA also transcends the properties of its material medium. Because chemical bonds do not determine the arrangement of nucleotide bases, the nucleotides can assume a vast array of possible sequences and thereby express many different biochemical messages.
If the properties of matter (i.e., the medium) do not suffice to explain the origin of information, what does? Our experience with information–intensive systems (especially codes and languages) indicates that such systems always come from an intelligent source—i.e., from mental or personal agents, not chance or material necessity. This generalization about the cause of information has, ironically, received confirmation from origin–of–life research itself. During the last forty years, every naturalistic model proposed has failed to explain the origin of information—the great stumbling block for materialistic scenarios. Thus, mind or intelligence or what philosophers call "agent causation" now stands as the only cause known to be capable of creating an information–rich system, including the coding regions of DNA, functional proteins, and the cell as a whole.
Because mind or intelligent design is a necessary cause of an informative system, one can detect the past action of an intelligent cause from the presence of an information–intensive effect, even if the cause itself cannot be directly observed. Since information requires an intelligent source, the flowers spelling "Welcome to Victoria" in the gardens of Victoria harbor in Canada lead visitors to infer the activity of intelligent agents even if they did not see the flowers planted and arranged.
Scientists in many fields now recognize the connection between intelligence and information and make inferences accordingly. Archaeologists assume a mind produced the inscriptions on the Rosetta Stone. SETI’s search for extraterrestrial intelligence presupposes that the presence of information imbedded in electromagnetic signals from space would indicate an intelligent source. As yet, radio astronomers have not found information–bearing signals coming from space. But molecular biologists, looking closer to home, have discovered information in the cell. Consequently, DNA justifies making what probability theorist William A. Dembski calls "the design inference."
Of course, many scientists have argued that to infer design gives up on science. They say that inferring design constitutes an argument from scientific ignorance—a "God of the Gaps" fallacy. Since science doesn’t yet know how biological information could have arisen, design theorists invoke a mysterious notion—intelligent design—to fill a gap in scientific knowledge. Many philosophers, for their part, resist reconsidering design, because they assume that Hume’s objections to analogical reasoning in classical design arguments still have force.
Yet developments in philosophy of science and the information sciences provide the grounds for a decisive refutation of both these objections. First, contemporary design theory does not constitute an argument from ignorance. Design theorists infer design not just because natural processes cannot explain the origin of biological systems, but because these systems manifest the distinctive hallmarks of intelligently designed systems—that is, they possess features that in any other realm of experience would trigger the recognition of an intelligent cause. For example, in his book Darwin’s Black Box (1996), Michael Behe has inferred design not only because the gradualistic mechanism of natural selection cannot produce "irreducibly complex" systems, but also because in our experience "irreducible complexity" is a feature of systems known to have been intelligently designed. That is, whenever we see systems that have the feature of irreducible complexity and we know the causal story about how such systems originated, invariably "intelligent design" played a role in the origin of such systems. Thus, Behe infers intelligent design as the best explanation for the origin of irreducible complexity in cellular molecular motors, for example, based upon what we know, not what we don’t know, about the causal powers of nature and intelligent agents, respectively.
Similarly, the "sequence specificity" or "specificity and complexity" or "information content" of DNA suggests a prior intelligent cause, again because "specificity and complexity" or "high information content" constitutes a distinctive hallmark (or signature) of intelligence. Indeed, in all cases where we know the causal origin of "high information content," experience has shown that intelligent design played a causal role.
Design theorists infer a past intelligent cause based upon present knowledge of cause and effect relationships. Inferences to design thus employ the standard uniformitarian method of reasoning used in all historical sciences, many of which routinely detect intelligent causes. We would not say, for example, that an archeologist had committed a "scribe of the gaps" fallacy simply because he inferred that an intelligent agent had produced an ancient hieroglyphic inscription. Instead, we recognize that the archeologist has made an inference based upon the presence of a feature (namely, "high information content") that invariably implicates an intelligent cause, not (solely) upon the absence of evidence for a suitably efficacious natural cause.
Second, contra the classical Humean objection to design, the "DNA to Design" argument does not depend upon an analogy between the features of human artifacts and living systems, still less upon a weak or illicit one. If, as Bill Gates has said, "DNA is similar to a software program" but more complex, it makes sense, on analogical grounds, to consider inferring that it too had an intelligent source.
Nevertheless, while DNA is similar to a computer program, the case for its design does not depend merely upon resemblance or analogical reasoning. Classical design arguments in biology typically sought to draw analogies between whole organisms and machines based upon certain similar features that each held in common. These arguments sought to reason from similar effects back to similar causes. The status of such design arguments thus turned on the degree of similarity that actually obtained between the effects in question. Yet since even advocates of these classical arguments admitted dissimilarities as well as similarities, the status of these arguments always appeared uncertain. Advocates would argue that the similarities between organisms and machines outweighed dissimilarities. Critics would claim the opposite.
The design argument from the information in DNA does not depend upon such analogical reasoning since it does not depend upon claims of similarity. As noted above, the coding regions of DNA have the very same property of "specified complexity" or "information content" that computer codes and linguistic texts do. Though DNA does not possess all the properties of natural languages or "semantic information"—i.e., information that is subjectively "meaningful" to human agents—it does have precisely those properties that jointly implicate an antecedent intelligence.
As William A. Dembski has shown in his recent book The Design Inference (1998), systems or sequences that have the joint properties of "high complexity and specification" invariably result from intelligent causes, not chance or physical–chemical necessity. Complex sequences are those that exhibit an irregular and improbable arrangement that defies expression by a simple rule or algorithm. A specification, on the other hand, is a match or correspondence between a physical system or sequence and a set of independent functional requirements or constraints. As it turns out, the base sequences in the coding regions of DNA are both highly complex and specified. The sequences of bases in DNA are highly irregular, non–repetitive, and improbable—therefore, complex. Moreover, the coding regions of DNA exhibit sequential arrangements of bases that are necessary (within certain fine tolerances) to produce functional proteins—that is, they are highly specified with respect to the independent requirements of protein function and protein synthesis. Thus, as nearly all molecular biologists now recognize, the coding regions of DNA possess a high "information content"—where "information content" in a biological context means precisely "complexity and specificity."
The design argument from information content in DNA, therefore, does not depend upon analogical reasoning since it does not depend upon assessments of degree of similarity. The argument does not depend upon the similarity of DNA to a computer program or human language, but upon the presence of an identical feature ("information content" defined as "complexity and specification") in both DNA and all other designed systems, languages, or artifacts. While a computer program may be similar to DNA in many respects, and dissimilar in others, it exhibits a precise identity to DNA in its ability to store information content (as just defined).
Thus, the "DNA to Design" argument does not represent an argument from analogy of the sort that Hume criticized, but an "inference to the best explanation." Such arguments turn, not on assessments of the degree of similarity between effects, but instead on an assessment of the adequacy of competing possible causes for the same effect. Because we know intelligent agents can (and do) produce complex and functionally specified sequences of symbols and arrangements of matter (i.e., information content), intelligent agency qualifies as a sufficient causal explanation for the origin of this effect. Since, in addition, naturalistic scenarios have proven universally inadequate for explaining the origin of information content, mind or creative intelligence now stands as the best and only entity with the causal power to produce this feature of living systems.
For almost 150 years many scientists have insisted that "chance and necessity"—happenstance and law—jointly suffice to explain the origin of life on earth. We now find, however, that orthodox evolutionary thinking—with its reliance upon these twin pillars of materialistic thought—has failed to explain the specificity and complexity of the cell. Even so, many scientists insist that to consider another possibility would constitute a departure from science, from reason itself.
Yet ordinary reason, and much scientific reasoning that passes under the scrutiny of materialist sanction, not only recognizes but requires us to recognize the causal activity of intelligent agents. The sculptures of Michaelangelo, the software of the Microsoft corporation, the inscribed steles of Assyrian kings—each bespeaks the prior action of an intelligent agent. Indeed, everywhere in our high–tech environment we observe complex events, artifacts, and systems that impel our minds to recognize the activity of other minds—minds that communicate, plan, and design. But to detect the presence of mind, to detect the activity of intelligence in the echo of its effects, requires a mode of reasoning—indeed, a form of knowledge—the existence of which science, or at least official biology, has long excluded. Yet recent developments in the information sciences and within biology itself now imply the need to rehabilitate this lost way of knowing. As we do so, we may find that we have also restored some of the intellectual underpinning of traditional Western metaphysics and theistic belief.
Stephen C. Meyer, who did his doctoral work in the history and philosophy of science at Cambridge University, is Associate Professor of Philosophy at Whitworth College and Senior Research Fellow at the Discovery Institute in Seattle.